From Human Videos to Robot Manipulation: A Survey on Scalable Vision-Language-Action Learning with Human-Centric Data
Abstract
Recent progress in generalizable embodied control has been driven by large-scale pretraining of Vision–Language–Action (VLA) models. However, most existing approaches rely on large collections of robot demonstrations, which are costly to obtain and tightly coupled to specific embodiments. Human videos, by contrast, are abundant and capture rich interactions, providing diverse semantic and physical cues for real-world manipulation. Yet, embodiment differences and the frequent absence of task-aligned annotations make their direct use in VLA models challenging.
This survey provides a unified view of how human videos are transformed into effective knowledge for VLA models. We categorize existing approaches into four classes based on the action-related information they derive: (i) latent action representations that encode inter-frame changes; (ii) predictive world models that forecast future frames; (iii) explicit 2D supervision that extracts image-plane cues; and (iv) explicit 3D reconstruction that recovers geometry or motion. Beyond this taxonomy, we highlight three key open challenges in this area: structuring unstructured videos into training-ready episodes, grounding video-derived supervision into robot-executable actions under embodiment and viewpoint heterogeneity, and designing evaluation protocols that better predict real-world deployment performance and transfer efficiency, thereby informing future research directions.

Key Contributions
Signal-centric taxonomy
A pipeline-based taxonomy of representation bridges that turn human videos into action-relevant signals, comparing the four routes by representation form, scalability, and grounding requirements.
Dataset map & signals
A systematization of representative human-video datasets along two axes — explicit 3D signals and scripted vs. in-the-wild collection — clarifying which supervision supports which transfer pipeline.
Challenges at three interfaces
Open problems at three critical interfaces: scalable episodization of unstructured videos, heterogeneity-aware grounding under embodiment/viewpoint mismatch, and deployment-predictive evaluation of transfer efficiency.
A Taxonomy of Representation Bridges
We organize prior work into four representation bridges that translate human video into action-relevant signals. Figure 2 shows the taxonomy, and Table 1 summarizes video sources, data scale, representations, and evaluated end-effectors.
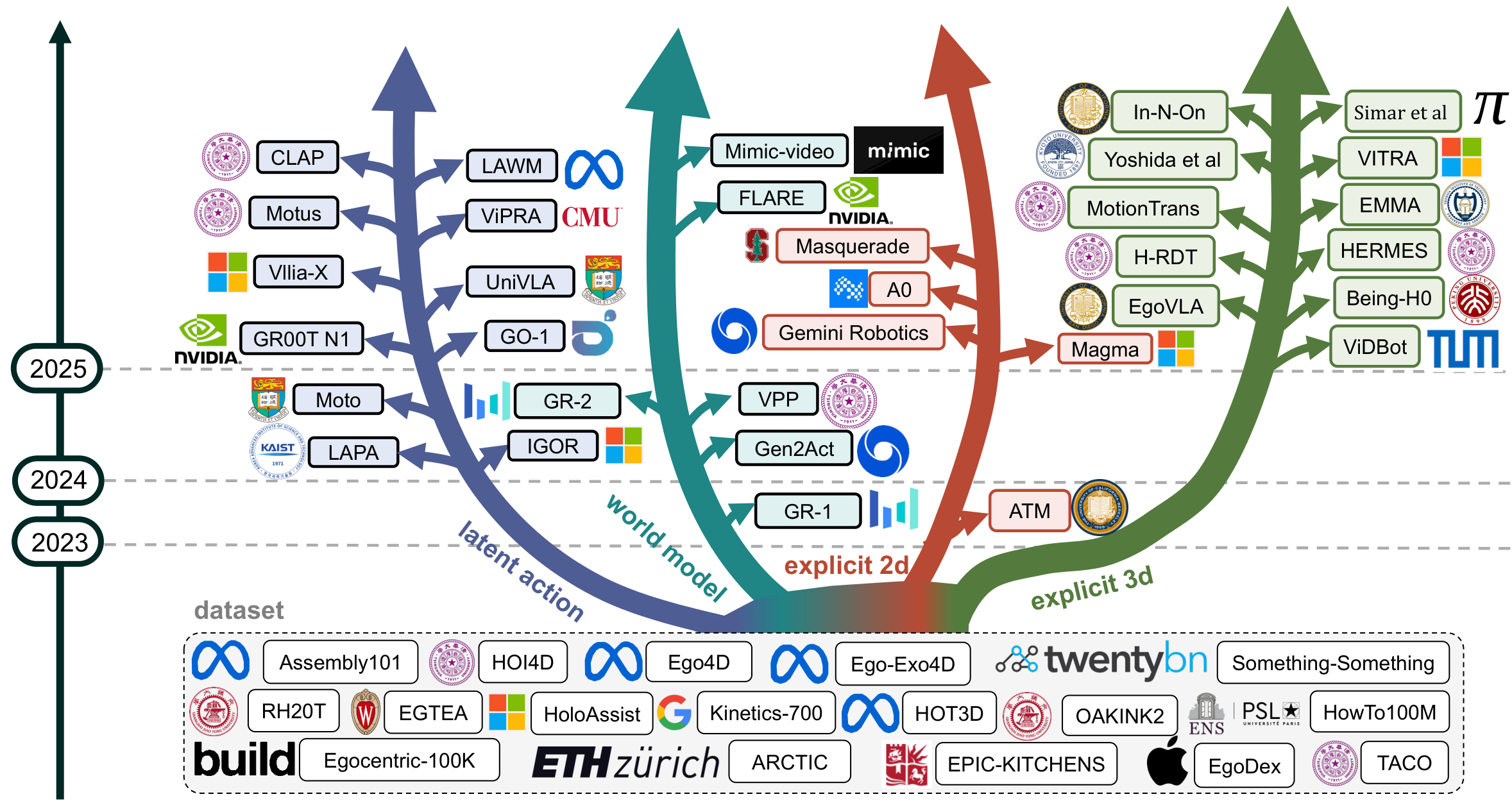
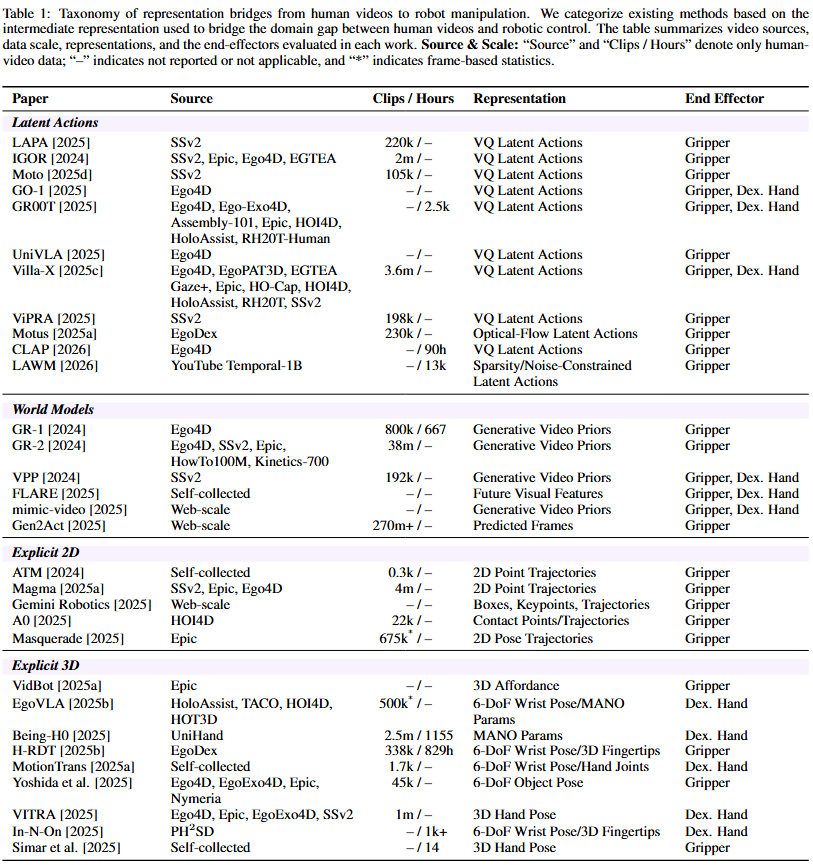
Latent Actions
ImplicitLearn compact latent tokens that capture motion changes from video with strong bottlenecks, and use them as action proxies. Representative works include LAPA, UniVLA, CLAP, and LAWM, but very compact tokens may under-represent high-DoF dexterity.
World Models
PredictivePredict future observations or features from current video and language, then transfer the learned dynamics to action prediction. Examples include GR-1/GR-2, FLARE, and Mimic-Video, with planning variants like Gen2Act; training cost and transfer efficiency remain key challenges.
Explicit 2D Representations
ExplicitUse 2D primitives such as keypoints, boxes, and trajectories as intermediate supervision. Representative works include ATM, Magma, Gemini Robotics, A0, and Masquerade; these cues are efficient but limited by depth and occlusion and can inherit label noise.
Explicit 3D Representations
ExplicitRecover 3D hand or object poses (often MANO-based) to align human motion with robot actions. Examples include EgoVLA, H-RDT, Being-H0, and VITRA; 3D grounding is strong, but accurate 3D estimation in the wild remains difficult.
Human-Centric Data for VLA Learning
We organize human-video datasets along two axes: whether they provide explicit metric 3D action labels and whether collection is scripted or unscripted. This framing clarifies which datasets can directly ground supervision into robot-executable actions versus those that require action inference from visual state changes.
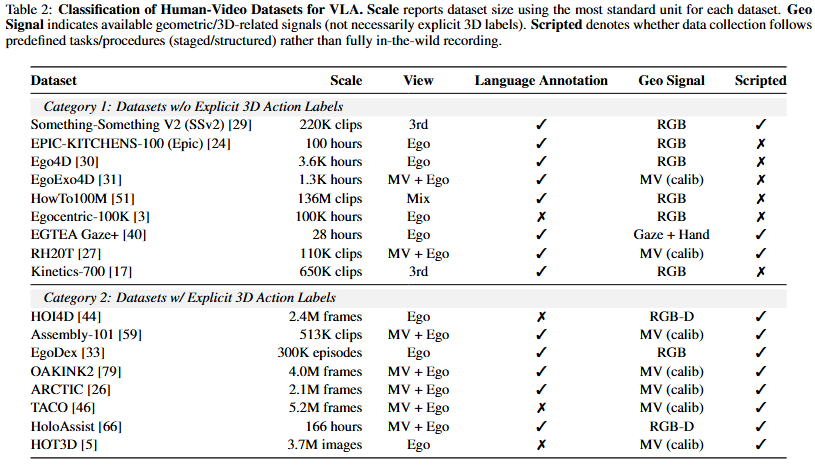
Datasets without explicit 3D action labels provide RGB videos with semantic annotations but lack metric hand/body trajectories. They primarily support latent-action and world-model approaches. Representative sources include SSv2, EPIC-KITCHENS, Ego4D, HowTo100M, and Ego-Exo4D. These datasets are large and diverse, but their unscripted nature often complicates episodization and instruction alignment.
Datasets with explicit 3D action labels are collected with instrumented setups (AR/VR, RGB-D, or motion capture) and provide 3D keypoints or parametric hand models (e.g., MANO). Examples include HOI4D, HOT3D, EgoDex, ARCTIC, TACO, Assembly101, OakInk2, and HoloAssist. They enable direct supervision but are typically smaller and more scripted, trading scale for annotation fidelity.
Challenges and Future Directions
We highlight three open challenges along the human-video-to-robot pipeline: episodization, heterogeneity, and evaluation.
Transforming videos to episodes
Web-scale videos are rarely segmented into training-ready episodes, and weak alignment between narration and manipulation makes supervision noisy. Future episodization should be driven by semantic and interaction cues (e.g., object state changes) rather than fixed windows.
Handling heterogeneity
Embodiment and viewpoint mismatches make retargeting under-constrained and observations inconsistent. More robust transfer likely requires embodiment-aware grounding and representations anchored to interaction outcomes instead of appearance.
Benchmarking and evaluation
Existing suites under-represent long-horizon, open-world diversity. Progress depends on protocols that report performance versus robot-data budgets, test robustness to viewpoint/embodiment shifts, and compare models with and without human-video pretraining under matched compute.