|
I am a Ph.D. candidate in Computer Science at the Institute for Advanced Study, Tsinghua University, advised by Prof. Baining Guo. I received my B.S. in Computer Science from the Qian Xuesen Honors College at Xi’an Jiaotong University. My research focuses on embodied AI, spatial reasoning, and multimodal large language models, especially vision-language-action systems for robotic perception, understanding, and decision-making. I am interested in building intelligent agents that can reason about complex physical environments and assist people in real-world scenarios. Email / Google Scholar / RedBook / WeChat / X |

|

|
Paper / Webpage arXiv 2026 We formalize full-scene household reasoning, where an agent must infer executable task structure from a complete household scene and a situated request. We propose TaskGround, a training-free Ground-Infer-Execute framework that grounds the scene into compact task-relevant slices before producing skill-level action sequences. On our new FullHome benchmark (400 human-validated household tasks), TaskGround substantially boosts success rates across proprietary and open-weight models, making Qwen3.5-9B competitive with GPT-5 while cutting input-token cost by up to 18×. |

|
Paper / Webpage / Code / Data / SlideLive ICLR 2026 🔥🔥🔥 Cited by DreamZero 🌟🌟🌟 We propose MV-RoboBench, a benchmark for evaluating the multi-view spatial reasoning capabilities of VLMs in robotic manipulation. |
|
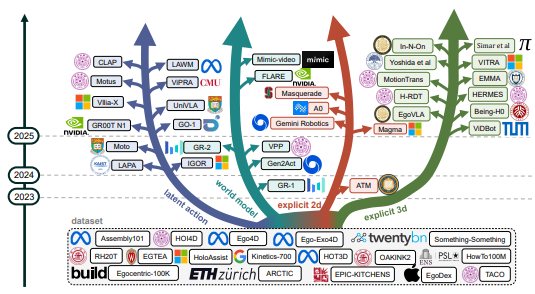
Paper / Webpage IJCAI 2026 Survey Track 🔥🔥🔥 We survey how to turn abundant human videos into actionable supervision for VLA models, organizing methods into four categories and outlining key challenges for reliable real-world transfer. |
|
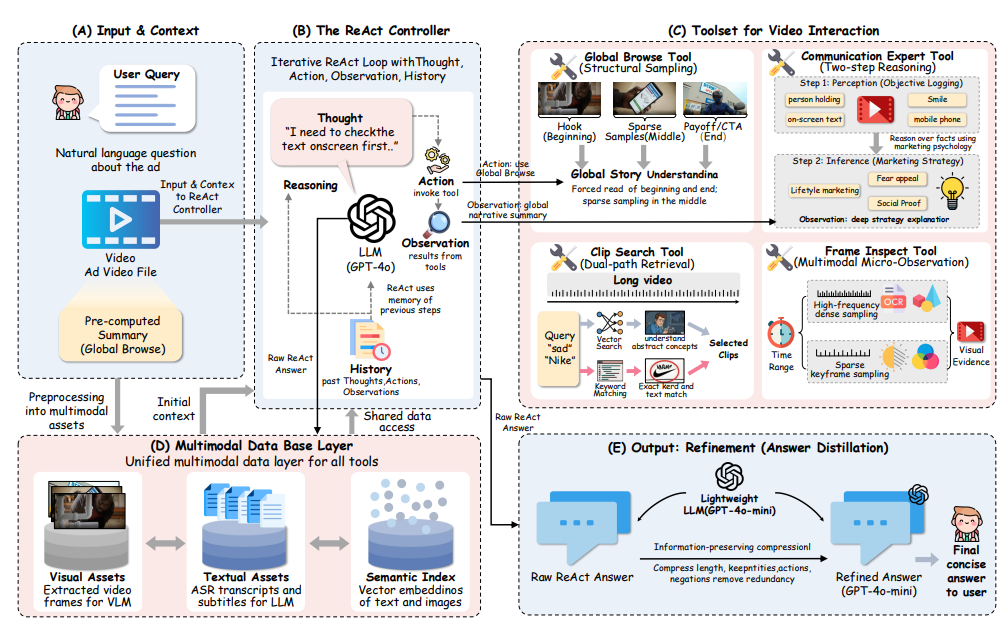
Paper ICML 2026 🔥🔥🔥 We propose AD-MIR, a two-stage framework that decodes advertising intent by first constructing a structured multimodal database via semantic retrieval and keyword matching, then reasoning over it with an iterative, evidence-grounded inquiry loop that mimics marketing expertise, achieving state-of-the-art on AdsQA. |
|
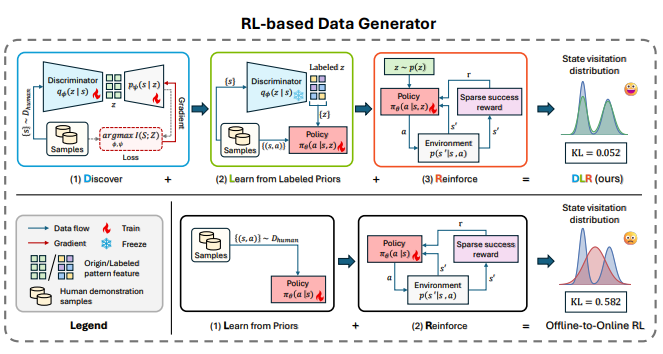
Paper arXiv 2025 We propose DLR, an information-theoretic multi-pattern RL framework that generates diverse, high-success manipulation trajectories for scalable VLA pretraining, improving transfer and showing better data-scaling than standard single-pattern RL. |

|
Paper / Dataset arXiv 2026 We introduce WorldReasonBench, a human-aligned benchmark that stress-tests video generators as future world-state predictors across four dimensions—World Knowledge, Human Centric, Logic Reasoning, and Information-Based reasoning—covering diverse tasks from physical dynamics and cultural understanding to spatial geometry and quantitative math. |
|
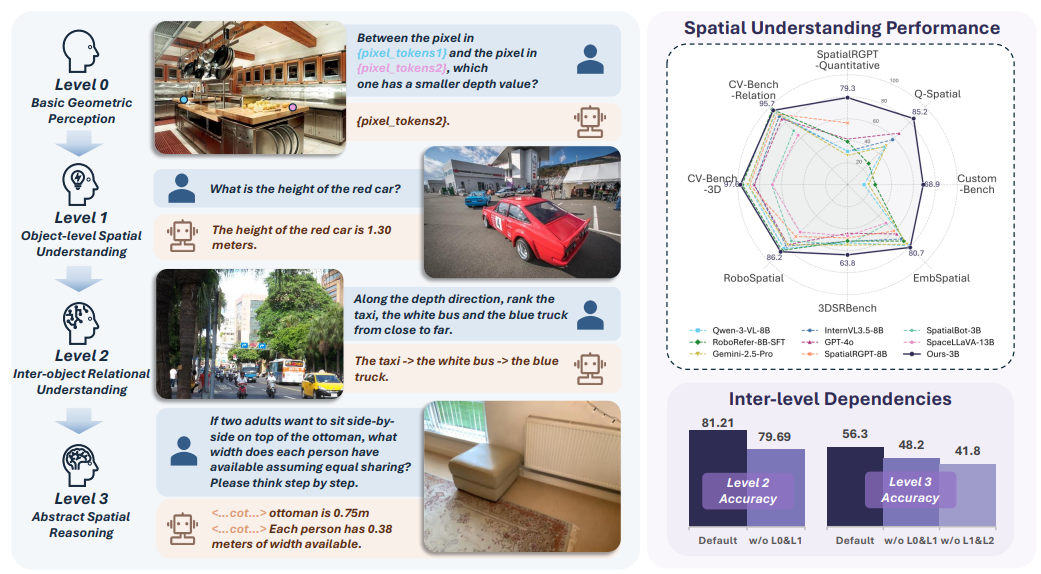
Paper / Webpage / Code CVPR 2026 🔥🔥🔥 We propose a hierarchical framework that decomposes 3D spatial understanding in VLMs into four progressive levels, and build an automated pipeline over ~5M images to generate 3D spatial VQA data for fine-tuning, achieving state-of-the-art on multiple spatial reasoning benchmarks. |

|
Paper / Webpage / Code ICRA 2026 🔥🔥🔥 We propose VITRA, a novel approach for pretraining Vision-Language-Action (VLA) models for robotic manipulation using large-scale, unscripted, real-world videos of human hand activities. My contribution: I focus on the data processing pipeline, leveraging HaWoR to reconstruct 3D hand poses from human-centric videos. |
|
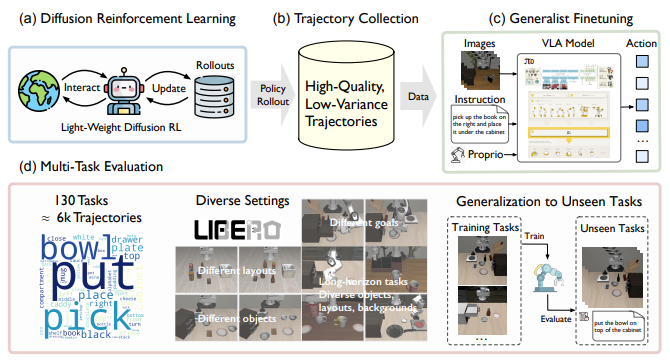
Paper arXiv 2025 We propose a diffusion policy optimization method that uses RL to autonomously generate smooth, low-variance long-horizon manipulation trajectories, enabling VLA training that outperforms models trained on human or Gaussian RL demonstrations on LIBERO. |
|
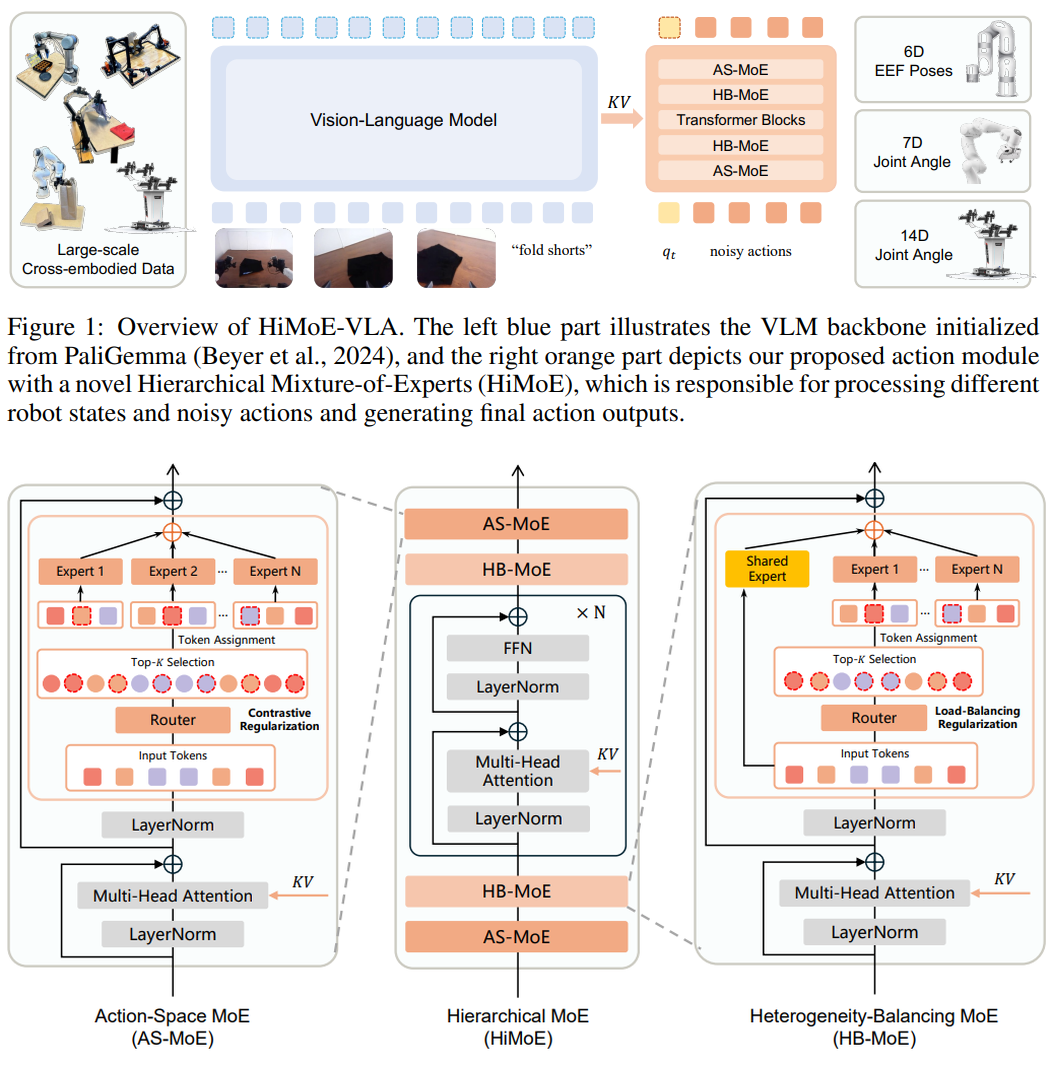
Paper / Code arXiv 2025 We propose HiMoE-VLA, a vision-language-action framework that tackles cross-embodiment heterogeneity via a Hierarchical Mixture-of-Experts action module, adaptively handling diverse action spaces, sensor configurations, and control frequencies to deliver consistent gains and robust generalization across simulation benchmarks and real-world robotic platforms. |
|
Paper / Code ICLR 2026 HSSBench is a multilingual (UN six languages) benchmark of 13,000+ expert-curated samples designed to evaluate MLLMs’ cross-disciplinary, concept-to-vision reasoning in Humanities and Social Sciences, revealing clear gaps even in state-of-the-art models. |
|
Paper NIPS 2025 AI4X-AC 2026 Oral We introduce MIRA, a medical time-series foundation model pretrained on 454B+ time points that handles irregular sampling and missingness to deliver stronger zero-shot and fine-tuned forecasting across datasets and tasks. |
|
|
Paper / Webpage ICRA 2025 We propose TransDiff, a diffusion-based single-view RGB-D depth completion method for accurate grasping of transparent objects. |
|
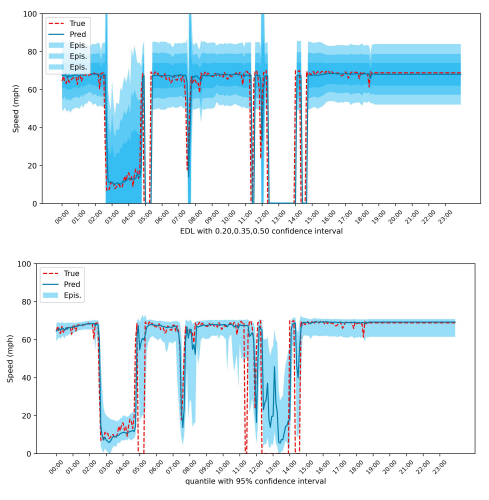
Paper CIKM 2024 Workshop We integrate evidential deep learning into DCRNN to provide sampling-free uncertainty quantification for spatiotemporal traffic forecasting, achieving improved predictive intervals measured by MIS. |
|
Tsinghua University, Beijing
2024 - Present
Ph.D of Computer Science
Institute for Advanced Study
Advisor: Baining Guo (IEEE&ACM Fellow)
|
|
|
Xi'an Jiaotong University, Xi'an
2020 - 2024
B.E. of Computer Science
Qian Xuesen Honors College
|
|
Microsoft Research Asia
Jul 2024 - Present
Spatial Intelligence Group
Role: Research Intern, working on Embodied AI.
Advisor: Yu Deng and Jiaolong Yang.
|
|
|
Microsoft Research Asia
Dec 2023 - Jun 2024
Vision Computing Group
Role: Research Intern, working on LLM for reasoning.
Advisor: Zheng Zhang.
|
|
Professional Service
Awards & Honors
|
|
This template is a modification to Jiayi Ni's website and Jon Barron's website. |